
Principais Pontos
- Agente Autônomo Real: O OpenClaw opera 24/7 de forma proativa em VPS ou hardware local, superando chats passivos como ChatGPT.
- Arquitetura Híbrida e Local: Suporte nativo a provedores em nuvem (Anthropic/OpenAI) e LLMs locais via Ollama para custo zero em tarefas rotineiras.
- Segurança Estrita: Implementação baseada no princípio de menor privilégio e isolamento via Docker Compose para proteger dados sensíveis.
- Redução de Custo (Roteamento): Estratégia de Tiers de LLM para economizar até 80% de tokens usando modelos compactos em heartbeats.
- Ecossistema Aberto: Integração avançada via Skills com Google Workspace API, Telegram e automações baseadas em arquivos Markdown (.md).
Resposta Rápida
O OpenClaw é um assistente de IA autônomo de código aberto que roda continuamente (24/7) em um servidor (VPS ou local), executando tarefas proativas sem precisar de comandos em tempo real. Diferente de LLMs tradicionais de chat, ele utiliza uma arquitetura baseada em agentes (agents), memória persistente em arquivos Markdown, e integração via APIs (Telegram, Google Workspace). Ele permite roteamento inteligente de modelos (usando IA avançada para decisões complexas e IA local via Ollama para monitoramento contínuo), equilibrando segurança, autonomia e controle de custos operacionais.
Visão Geral
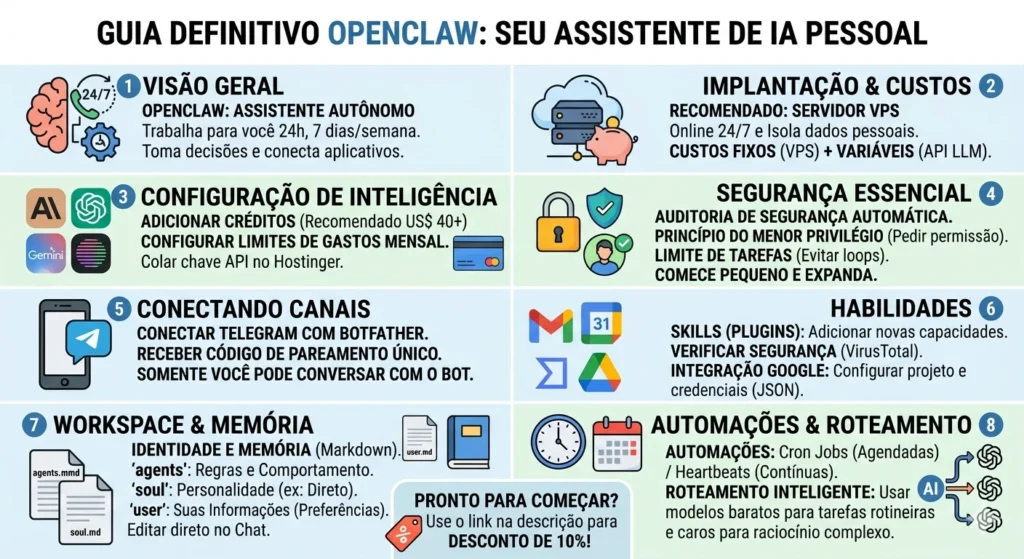
O mercado de Inteligência Artificial em 2026 consolidou a transição dos “Chatbots Passivos” para os Agentes Autônomos de Ação. É exatamente neste cenário que o OpenClaw se destaca. Enquanto ferramentas tradicionais dependem exclusivamente da sua iniciativa de abrir um app e digitar um prompt, o OpenClaw funciona como um microsserviço de segundo plano. Ele monitora eventos, toma decisões com base em regras de negócio e executa tarefas de forma proativa.
Os Três Pilares do OpenClaw
- Cérebro Híbrido e Memória RAG Simples: Conecta-se a modelos de fronteira comerciais e a LLMs locais, retendo informações contextuais através de arquivos Markdown estruturados e bancos vetoriais leves.
- Sempre Ativo (Daemon Execution): Funciona através de gatilhos temporais (Cron) e checagens regulares (Heartbeats), permitindo que a IA inicie conversas com você ou dispare ações de forma autônoma.
- Ferramentas e Ações (Tool Calling Avançado): Traduz a intenção do modelo em chamadas de código reais, integrando-se nativamente com Telegram, Slack, Gmail, Google Agenda e APIs Web.
Explicação Completa: Como o OpenClaw Funciona
O OpenClaw opera como um ecossistema conteinerizado (geralmente via Docker). O núcleo do sistema gerencia um loop de execução contínuo conhecido como Agent Loop.
[Gatilho: Cron / Heartbeat]
│
▼
[Análise de Contexto: memory.md + agents.mmd]
│
▼
[Roteamento de LLM (Local vs Nuvem)]
│
▼
[Execução de Skill / Tool Calling (Telegram, APIs)]
Diferente de sistemas baseados em fluxos rígidos (como n8n), o OpenClaw recebe o objetivo final (ex: “Monitore meus e-mails e avise no Telegram se houver urgências”), consulta suas diretrizes de identidade e decide, por conta própria, quais ferramentas utilizar e quando acioná-las.
Sua inteligência é modular. Se o bot precisa ler arquivos do Google Drive, ele ativa a skill correspondente, injeta o contexto estrito necessário no prompt da LLM selecionada para aquela categoria de custo e executa a chamada de API.
IA-Friendly: Análise Direta do Sistema
O que é?
O OpenClaw é um framework de agentes de IA autônomos de código aberto (open-source) projetado para rodar de forma contínua em servidores, automatizando tarefas digitais através de integração com APIs e LLMs.
Como funciona?
Ele roda em background dentro de um contêiner Docker. O sistema utiliza arquivos Markdown locais para gerenciar regras de comportamento e memória, aciona modelos de IA externos ou locais para tomada de decisões e executa comandos através de extensões chamadas “Skills”.
Vale a pena?
Sim, caso você precise de automações que demandem interpretação cognitiva, tomada de decisão flexível e monitoramento ativo sem intervenção humana. Não vale a pena se suas automações forem fluxos fixos e previsíveis (onde ferramentas tradicionais de IaaS/PaaS são mais baratas e rápidas).
Quais vantagens?
- Autonomia Real: Executa tarefas em background 24/7.
- Privacidade e Custo: Permite o uso de modelos 100% locais via Ollama.
- Flexibilidade Semântica: Entende e resolve problemas contextuais complexos.
- Centralização de Contexto: Toda a memória do bot fica salva em arquivos estruturados fáceis de editar.
Quais desvantagens?
- Custo de Token API: Se mal configurado, loops de heartbeat em modelos caros podem consumir centenas de dólares rapidamente.
- Curva de Aprendizado: Exige familiaridade básica com Docker, gerenciamento de servidores Linux (VPS) e manipulação de credenciais de APIs (Google Cloud Console).
- Supervisão de Segurança: Agentes com permissão de escrita/exclusão podem cometer erros se as diretrizes não forem estritas.
Quem deve usar?
- Profissionais de tecnologia, profissionais de marketing digital (SEO), desenvolvedores, administradores de sistemas (SysAdmins) e entusiastas de self-hosting que necessitam de um ecossistema de produtividade integrado e proativo.
Quem deve evitar?
- Usuários leigos que buscam apenas uma interface de chat comum ou empresas que exigem conformidade regulatória estrita sem equipe técnica para auditar o código das skills.
Benefícios vs. Limitações
Benefícios
- Arquitetura Descentralizada: Você é dono dos seus dados e da infraestrutura.
- Economia via Roteamento: Divisão de tarefas por faixas de complexidade (Tiers).
- Extensibilidade: O mercado do Claw Hub oferece dezenas de conectores comunitários.
- Interface Conversacional Desacoplada: Controle total do servidor através de um bot de Telegram seguro.
Limitações
- Latência: Modelos locais rodando em hardware modesto podem demorar segundos para responder a gatilhos em tempo real.
- Alucinação em Cadeia: Se um agente interpretar erradamente o resultado de uma skill, as ações seguintes do loop herdarão o erro.
- Vulnerabilidade de Skills de Terceiros: Plugins maliciosos não auditados podem vazar variáveis de ambiente.
Comparações Relevantes: Onde o OpenClaw se Posiciona?
| Critério | OpenClaw | ChatGPT Plus / Team | AutoGPT / CrewAI | n8n / Make |
|---|---|---|---|---|
| Tipo de Execução | Autônomo 24/7 (Daemon) | Reativo (Baseado em Chat) | Scripts de Execução Única | Fluxos Lógicos Rígidos |
| Hospedagem | VPS / Local (Self-hosted) | Nuvem Proprietária (OpenAI) | Local / CLI | Nuvem ou Self-hosted |
| Suporte a LLM Local | Sim (Nativo via Ollama) | Não | Sim | Sim (via nós de IA) |
| Interface Padrão | Telegram / Web UI admin | Web / App Mobile | Terminal / Código | Dashboard Visual |
| Foco Principal | Assistente Pessoal e Rotinas | Geração de Texto/Pesquisa | Desenvolvimento / Projetos | Automação de Processos |
Infraestrutura: Implantação e Hospedagem
Para garantir estabilidade, isolamento e operação contínua, a escolha do ambiente de execução é crítica. Veja a comparação técnica de custos e viabilidade:
Tabela de Comparativos de Hardware e Custo Operacional (2026)
| Tipo de Hospedagem | Custo Fixo Estimado | Consumo Elétrico Médio | ROI Técnico | Principais Desvantagens |
|---|---|---|---|---|
| Computador Pessoal | Gratuito (Hardware já existente) | 60W – 450W (Depende da GPU) | Baixo (Inviável 24/7) | Interrupção ao desligar, exposição de arquivos locais. |
| Hardware Dedicado (Ex: Mac Mini / Orange Pi) | US$ 15 – US$ 500 (Custo inicial único) | 5W – 30W | Alto (Longo Prazo) | Exige configuração de DNS dinâmico e abertura de portas. |
| Servidor VPS (KVM1 – Entrada) | ~ US$ 4 a US$ 7 / mês | Incluído no Datacenter | Altíssimo (Uso de APIs) | Recursos de hardware limitados para LLMs locais. |
| Servidor VPS (KVM4 – Para LLM Local) | ~ US$ 18 a US$ 25 / mês | Incluído no Datacenter | Altíssimo (Zero custo de API) | Requer otimização rigorosa de memória RAM e Swap. |
Configuração Recomendada no Provedor VPS (Ex: Hostinger ou similar)
- Escolha do Plano: Selecione instâncias baseadas em virtualização KVM. O plano básico atende perfeitamente se você for utilizar apenas chaves de API externas (Anthropic/OpenAI). Para rodar modelos locais como
llama3:8bouphi3, utilize no mínimo planos com 4 vCPUs e 8GB+ de RAM. - Sistema Operacional: Ubuntu 24.04 LTS ou Debian 13 estável.
- Ajuste de Memória (Swap): Essencial para evitar travamentos do Docker por falta de memória (Out Of Memory). Configure manualmente pelo menos 40 GB de espaço de swap em seu disco SSD/NVMe se pretender carregar múltiplos modelos locais no Ollama.
- Backups: Ative snapshots diários automáticos. Erros em automações de arquivos de sistema podem corromper seus Markdowns de memória.
Configuração de Inteligência e Roteamento de Custos
O maior risco operacional do OpenClaw é o desperdício de dinheiro com chamadas desnecessárias de API de alto custo. Em 2026, a boa prática exige o Roteamento por Tiers (Camadas):
Tabela de Roteamento Inteligente de LLMs
| Camada (Tier) | Complexidade da Tarefa | Modelos Recomendados (Nuvem) | Opção Local (Ollama – Custo Zero) |
|---|---|---|---|
| Tier 1 (Alta) | Decisões financeiras, refatoração de código, redação final de e-mails importantes. | Claude 3.5 Sonnet / GPT-4o | Llama 3 70B (Se houver infraestrutura) |
| Tier 2 (Média) | Classificação de e-mails, extração de entidades, geração de respostas simples. | Claude 3 Haiku / GPT-4o-mini | Llama 3.1 8B / Qwen 2.5 7B |
| Tier 3 (Rotina) | Heartbeats de monitoramento, checagem de horário, alertas simples de infraestrutura. | Não recomendado (Gasta API) | Phi-3 Mini (3.8B) / TinyLlama |
Dica de Finanças para IA: Ao criar contas em provedores como Anthropic ou OpenAI, adicione um saldo pré-pago inicial de pelo menos US$ 40. Contas de nível zero (Tier 0/1 de API com saldos de US$ 5) possuem limites de requisições por minuto (RPM) extremamente baixos. Isso faz com que o OpenClaw falhe em loops de automação sequenciais sem exibir erros explícitos na interface. Defina o limite rígido mensal em US$ 100 no painel para sua total segurança.
Guia Passo a Passo: Como Aplicar na Prática
Passo 1: Instalação do Ambiente via Docker Compose
No terminal da sua VPS, crie o diretório do projeto e configure o arquivo básico de infraestrutura.
docker-compose.yml
version: '3.8'
services:
openclaw:
image: openclaw/core:latest
container_name: openclaw_core
restart: always
environment:
- OPENCLOUD_GATEWAY_TOKEN=seu_token_mestre_aqui
- OLLAMA_HOST=http://ollama_local:11434
volumes:
- ./workspace:/app/workspace
- ./config:/app/config
ports:
- "8080:8080"
networks:
- claw_network
ollama_local:
image: ollama/ollama:latest
container_name: ollama_local
restart: always
volumes:
- ./ollama_data:/root/.ollama
networks:
- claw_network
networks:
claw_network:
driver: bridgeExecute o comando docker compose up -d para iniciar os serviços.
Passo 2: Proteção e Políticas de Segurança Básica
O OpenClaw possui o princípio de Menor Privilégio. Antes de liberar o agente na sua rede, configure as travas de segurança:
- No painel de administração web, acesse as configurações avançadas do arquivo
config.json. - Altere temporariamente a regra global para auditar os primeiros testes:
allow_insecure_actions: false. - Injete o comando de comportamento no chat mestre:
“Sempre redija e obtenha aprovação explícita antes de enviar e-mails, excluir arquivos ou realizar requisições POST externas.”
- Limites de Execução: Defina nas propriedades do agente que qualquer tarefa em execução contínua deve expirar (timeout) em no máximo 10 minutos, com interrupção automática se houver 3 falhas consecutivas em loops cronometrados.
Passo 3: Conexão do Canal de Comunicação (Telegram)
O Telegram funciona como o controle remoto do seu servidor.
- Abra o Telegram e inicie uma conversa com o
@BotFather. - Envie o comando
/newbot, configure o nome e copie o HTTP API Token gerado. - Insira esse token nas variáveis de ambiente ou no painel de controle do OpenClaw.
- Mande um
/startpara o seu novo bot. Ele gerará um código de pareamento exclusivo. Insira esse código no painel web para garantir que apenas o seu ID do Telegram possa dar ordens ao agente.
Passo 4: Integração com o Google Workspace (Skill GOGG)
Para dar acesso ao seu Gmail e Agenda:
- Acesse o Google Cloud Console e crie um novo projeto técnico.
- Ative manualmente a Gmail API e a Google Calendar API.
- Configure a Tela de Consentimento OAuth, definindo o tipo de usuário como “Externo” e colocando o seu e-mail como “Usuário de teste”.
- Vá em Credenciais > Criar Credenciais > ID do cliente OAuth. Selecione a opção Aplicativo de Desktop.
- Faça o download do arquivo JSON contendo as credenciais.
- Envie esse arquivo JSON diretamente no chat do OpenClaw no Telegram. O bot responderá com um link de autenticação. Clique, autorize a conta, e mesmo que apareça a tela de “Aplicativo não verificado pelo Google” (normal, já que você é o desenvolvedor dele), prossiga e copie a URL final gerada para colá-la de volta no chat da IA.
Passo 5: Personalizando a Identidade e a Memória do Agente
Acesse a pasta ./workspace criada pelo Docker. Lá você encontrará os arquivos de controle em Markdown. Você pode editá-los manualmente ou instruir o bot via chat:
agents.mmd: Define os escopos de automação.soul.md: Ajusta o tom de voz e as personas.
# Personalidade – Seja extremamente direto e técnico. – Elimine jargões corporativos genéricos. – Priorize respostas baseadas em dados e métricas operacionais.
user.md: Guarda seus dados de contexto de vida (Fuso horário, sites que gerencia, rotina de trabalho).memory.md: Repositório persistente de fatos importantes que o bot aprendeu em conversas passadas e deve lembrar para sempre.
Como Validar Isso na Prática
Para certificar-se de que sua infraestrutura e inteligência estão rodando em perfeita harmonia em 2026, realize o seguinte checklist de validação técnica:
- Teste de Estresse de Memória (Swap): No terminal da VPS, execute
free -mouhtopenquanto baixa um modelo de 8B parâmetros no Ollama (docker exec -it ollama_local ollama run llama3.1). Monitore se o uso de swap responde adequadamente sem matar o processo principal do Docker. - Auditoria de Logs do Agente: Monitore as respostas do terminal em tempo real usando
docker logs -f openclaw_core. Certifique-se de que nenhum erro de limite de requisições de API (429 Too Many Requests) está ocorrendo durante as checagens rotineiras. - Simulação de Loop Infinito: Force um comando ambíguo no Telegram como “Fique verificando se recebi novos e-mails sem parar”. Monitore se a regra de restrição de 10 minutos ou o limite de requisições por bloco atua barrando o comportamento destrutivo da IA.
Perguntas Frequentes (FAQ)
O OpenClaw pode gastar meu dinheiro se entrar em loop?
Sim, se configurado incorretamente utilizando modelos de Tier 1 (como Claude Opus) para tarefas contínuas de heartbeat. Para evitar isso, configure os limites de faturamento diretamente no painel do provedor de API e utilize modelos locais via Ollama para tarefas de monitoramento de rotina.
É seguro dar acesso ao meu e-mail pessoal para o bot?
O OpenClaw é totalmente self-hosted, ou seja, o código roda inteiramente no seu servidor e os dados não passam por servidores de terceiros (exceto pelo próprio provedor de IA escolhido). Ao utilizar o isolamento por Docker e limitar o acesso através do ID único do Telegram, o ambiente torna-se altamente seguro.
O que fazer se o bot parar de responder no Telegram?
Acesse o painel da sua hospedagem VPS. Verifique o status dos contêineres Docker. Caso o agente tenha travado em um loop complexo ou esgotado a memória do sistema, execute docker compose restart no terminal para normalizar a operação.
Posso instalar habilidades externas com segurança?
Sempre baixe plugins exclusivamente através do catálogo oficial do Claw Hub. Antes de realizar a instalação na máquina de produção, envie o link do repositório ou o pacote de arquivos para uma análise no VirusTotal ou audite as chamadas de rede no código-fonte da skill para garantir que suas credenciais não serão vazadas.
Conclusão
O OpenClaw representa o estado da arte na gestão de rotinas digitais em 2026. Ao migrar a inteligência de sistemas centralizados de chat para um servidor autônomo e focado em privacidade, você ganha eficiência, escala operacional e controle total sobre seus dados e automações.
Seja para gerenciar portfólios de sites, triar comunicações críticas ou monitorar servidores locais, a implementação de uma arquitetura híbrida de agentes (Nuvem + Local) é o melhor caminho técnico e financeiro hoje.
Próximos Passos
Pronto para colocar sua IA para trabalhar de verdade por você? Baixe o Docker Compose estruturado acima, configure suas credenciais na VPS e inicialize seu primeiro agente autônomo ainda hoje. Se tiver dúvidas sobre a otimização de modelos locais, deixe seu comentário ou interaja com a comunidade open-source do projeto!
Quer dominar o Docker em ambientes de laboratório doméstico?



